Great People of tomorrow, every perfume starts with one ingredient but it is
the last one that makes it come to life.
Hi! and Welcome! To all esteemed student who are trying to pursue their dreams
irrespective of their departments and previous experience.
Everyone is welcome. Here “Everyone” is not a metaphor, “Everyone” means
everyone.
Open source is not just “GSoC”. It is a lot about, idea, ego, altruism,
expression and satisfaction. From software to hardware to information anything
can be opensource. We do open-source because we love to. “GSoC” is just a good
motivation to start.
Some famous open source projects:
Firefox, Linux, Ubuntu, VLC.
Now coming back to KWoC, common problems faced and how to be prepared.
Psychological Barriers :- Completing KWoC requires you to overcome a
statement “I have just started with coding” or “These are State of Art things,It
requires a lot of experience”. I will easily term these statements as myths or
excuse.
Why these thoughts arise?
From project info. You will read fancy terms as “Scraping” “Audio-recognition”
“Natural Language Processing” “Deep Learning” “Networking” and you will lose
your heart. But the matter of truth is that project info tells you just about
what that project really does, not about the process how it performs that task.
In most of the projects mentioned, you are not going to implement everything
yourself and you don’t need to read everything present in the codebase. There
are pre-implemented library for most of state of art things, you just need to
learn some basic info about how to use these libraries.
Most of the software development is based on basic conditional statements,
libraries and lot of common sense.
Mentor Problem:- A lot of time there is a problem in response of mentor. A
lot of time mentor doesn’t respond in a helpful way or doesn’t respond at all.
Let me tell you a ravishing truth “This phenomenon happens in GSoC as well”.
Really you can’t help. Now what, you are in shoes of Robert frost, “Two roads
diverged in a yellow wood, And sorry I could not travel both”, either you can
become hopeless again and take a road more traveled or you can make it a
memorable event where you overcame your mediocrity. Try some other project with
similar portfolio. The cycle is shortlist project, talk to mentor, if you find
him convincing or if you think you can do project without his guidance then only
proceed, then code debug and repeat.Bug co-ordinator, but mark my word if you
are bugging anyone it’s your responsibility to respect his/her time, give back
your effort or remember that “Karma is a bitch”.
**Ubuntu:-**If you are new to ubuntu, “KWOC is going to be really awesome” .
Because you will remember this winter for like 1–2 years, because if you are
high on grit you will be going through a lot of learning shit. Okay, Siri is
here to your rescue, Ubuntu is nothing like Windows but considering you as a
Windows user, Instead of .exe there are other methods to install applications.
 Here is some Chinese wisdom for you my friend.
Here is some Chinese wisdom for you my friend.
There is terminal in ubuntu (ctrl + alt + t). Here is an important
[link] to
make you little aware of terminal. Get aware of this blog, terminal is quite
important for software development. Here is the
**[chest] of all beginner
friendly links.How to install software and
libraries[link].
You don’t need to learn everything at one go. As you start coding and setting up
environment for your respective project refer to these link as per need. If you
have not installed Ubuntu then visit this
[link]**.
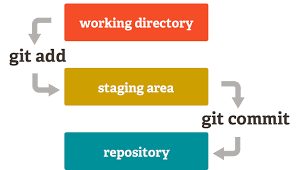
Git:- A command line tool to save different versions of your code wrt to
changes. Nothing more or less than that. People have complicated this
unnecessarily. It also interacts with Github and Bitbucket.
One of the best places to learn git is Learn Git
Branching
Starter pack of git :-
a) If you have installed Ubuntu very recently then for installation of git
sudo apt update && sudo apt install git
b) When you use git for the first time, you’ll have to configure it with details
matching with your GitHub profile.
git config — global user.name “
”
git config — global user.email “
”
c) If you are behind a proxy server then to configure git to access Github.
git config — global http.proxy 172.16.2.30:8080
d) Then login in your Github account.
This is just a sample. Change URL according to your project. Don’t just
blindly copy paste. Read instruction properly.
e) Visit this link Kossiitkgp website
repo [Visit your respective
project link].
f) On top right of that window click on watch button and pick watching option
g) Beside that button is star, star it as well, then there is fork button, click
on fork button.
h) Then you will be automatically directed to your forked window.
k) Click on that green button of clone or download.
l) When you click there, a menu appears where there is an option to copy link
but ensure that you copy the link is in this format
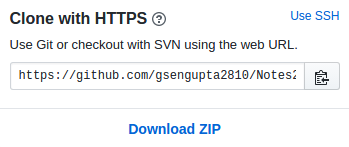
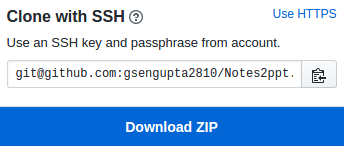
And not in this format:
m) Then press ctrl+alt+t
n)Then enter in terminal “git clone ” and then press ctrl+shift + v and then hit
enter (hitting enter is an untold rule).
git clone
o) cd kossiitkgp.github.io [change according to name of your project]
p) Then enter in terminal git remote add upstream and then press ctrl+shift+v
git checkout -b newbranch
r) If you can, edit some files in cloned folder (using git clone)for productive
use, save your changes by ctrl + s (if using sublime or gedit etc) .
s) Then properly review your changes then type this command in terminal in
already opened terminal.
git add -A
git commit -m “
”
git push origin
v) Enter your username and password. While entering password you will not see
anything
w) Done
x) Then visit
https://github.com/your-user-name(plz
change)/kossiitkgp.github.io
y) Then click on pull request then click on create new pr.(Check two branches
which you are comparing)
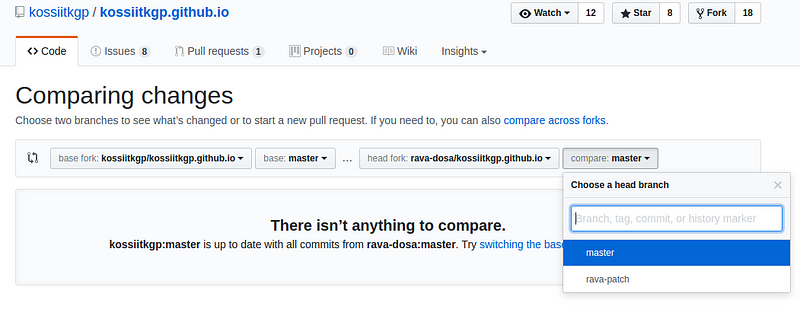
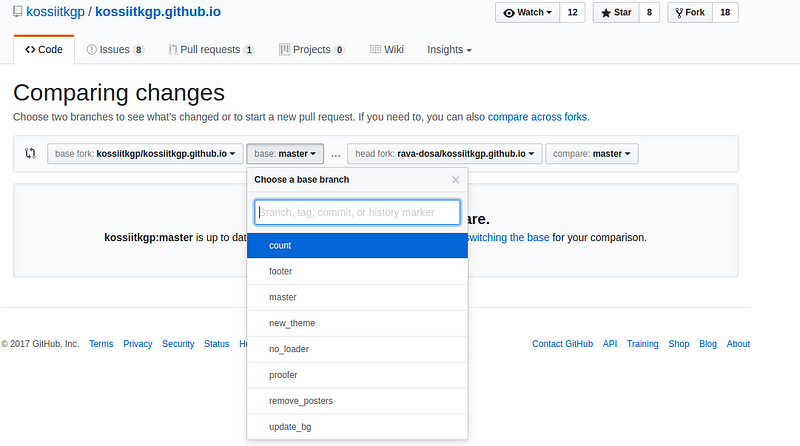
z) If you are sending pr after few days of cloning then before git push
first do
git pull
**(there are other methods as well like fetch and rebase) **or face the wrath of
merge conflict.
For proper crisp tutorial read
[this].
Github:- It is just a website(like Fb/Orkut) where pull request are similar
to Fb’s friend request. It is definitely more productive and useful.
But a more complicated definition
“GitHub is a web-based Git or version control repository and Internet hosting
service. It is mostly used for code. It offers all of the distributed version
control and source code management (SCM) functionality of Git as well as adding
its own features. It provides access control and several collaboration features
such as bug tracking, feature requests, task management, and wikis for every
project.”
Definitely, it gives a lot more insight only if you understand the terminology
:) :)
Reading codebase:- My steps would be:
A)
1. Setup a source insight( or any good source code browser you use)
workspace/project with all the source, header files, in the code base. Browsing
at a higher level from the top most function(main) to lowermost function. During
this code browsing, keep making notes on a paper/or a word document tracing the
flow of the function calls. Do not get into function implementation
nitti-gritties in this step, keep that for a later iterations. In this step keep
track of what arguments are passed on to functions, return values, how the
arguments that are passed to functions are initialized how the value of those
arguments set modified, how the return values are used ?
2. After one iteration of step 1, after which you have some level of
understanding of code and data structures used in the code base, setup
a…………………..[source]
B)
-
Identify why I’m reading code. Could be to understand an algorithm, see
different coding style, learn a language, find a defect, figure out a
workaround, understand a badly documented feature, know how to extend a feature,
make a plugin, discover how to exploit a feature beyond the initial intents, …
-
Find where to start reading. That could be the main/index file of the
application or library, a manifest. Or you could search the code for a
documented
feature……………….[source]
Googling:- Google any error which comes while development.This
[URL]
is in different context though. But you can get some idea. If you face any
problem while development just translate your problem to words and search, if
you are not getting solution reframe your problem and then search again. Before
asking anyone perform the above instruction at least two times.
Learning:- Learn what you google. If you are just googling and not learning
you are equally dependent as you were before. Here learning refers to mugging.
**Libraries:-**This is the basic difference b/w Windows and Ubuntu , In Windows,
we install whole everything to do something but in Ubuntu, we install something
to do a lot of thing. A minimalistic approach towards development.
As one of the member of open-source community, I would like you to introduce to
its manifesto
We need to take information, wherever it is stored, make our copies and share
them with the world. We need to take stuff that’s out of copyright and add it to
the archive. We need to buy secret databases and put them on the Web. We need to
download scientific journals and upload them to file sharing networks. We need
to fight
for……….[source]
Collective intelligence — multinational, multiagency, multidisciplinary,
multidomain information-sharing and sense-making — is the only means of
obtaining near-real time understanding of complex systems sufficient to achieve
resilience in the face of changes. Many of these changes, including biospheric
ones such as climate change and depletion of planetary resources, are the result
of human activity and industry in the last three
centuries.[source]
In a more beautiful way
“Beneath the mask, there is more than flesh, there is an idea and ideas are
bulletproof”
With Love From:
Kharagpur Open Source Society